트리의 지름(Gold 3)
문제
1167번: 트리의 지름
트리가 입력으로 주어진다. 먼저 첫 번째 줄에서는 트리의 정점의 개수 V가 주어지고 (2 ≤ V ≤ 100,000)둘째 줄부터 V개의 줄에 걸쳐 간선의 정보가 다음과 같이 주어진다. 정점 번호는 1부터 V까지
www.acmicpc.net
접근법
이 문제는 BFS/DFS를 두 번 탐색하여 풀 수 있다. 아래의 그림을 보자.
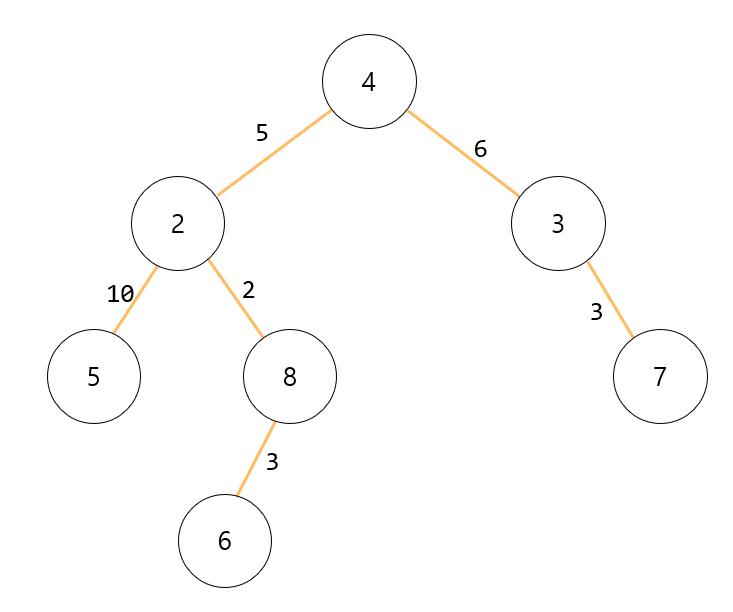
위와 같은 트리가 주어졌을 경우 트리의 지름은 아래와 같이 노드 5에서 출발해서 노드 7로 연결하는 길이인 24이다.
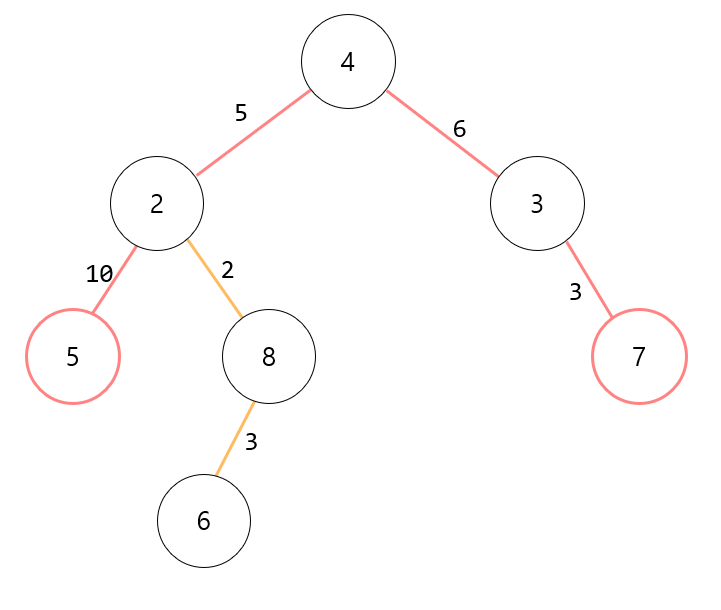
이문제를 풀기 위해서 생각해볼 점은 "임의의 노드에서 가장 멀리 떨어진 노드는 반드시 '노드 5' 혹은 '노드 7'이다."라는 점이다. 임의의 노드에서 탐색을 진행하여 그 노드와 가장 멀리 떨어져 있는 말단 노드를 구하면 반드시 양 끝단에 있는 노드가 나온다는 말이다. 이를 조금 더 직관적으로 이해하기 위해서 트리를 아래의 그림처럼 표현해 보았다.
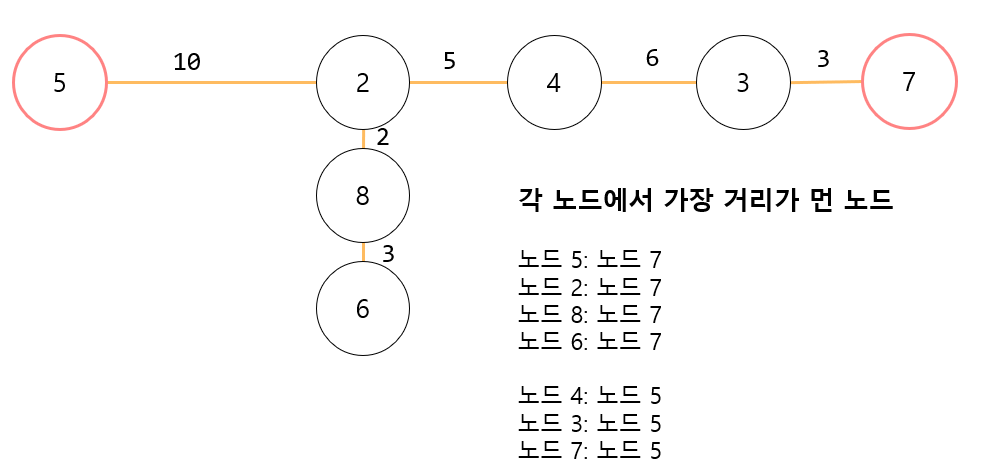
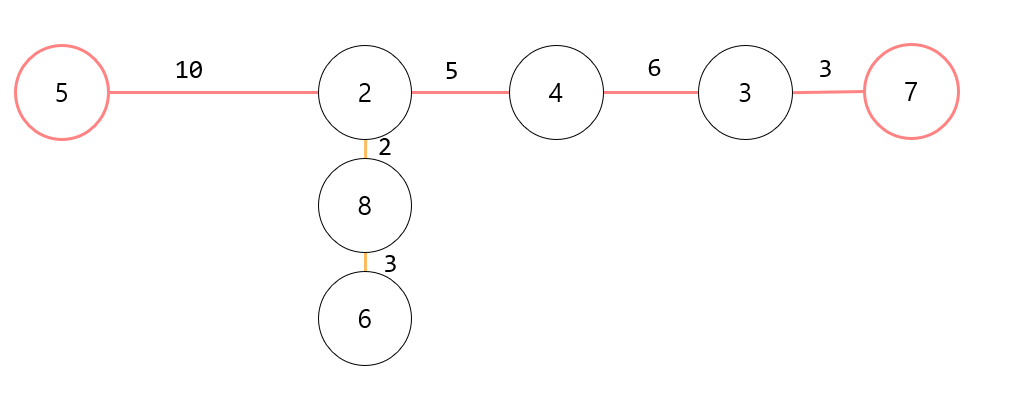
위 그림에서처럼 어떠한 노드에서 탐색을 시작하더라도 가장 멀리 떨어져있는 노드는 반드시 '노드 7' 혹은 '노드 5'가 나온다. 그리고 '노드 7' 혹은 '노드 5'에서 다시 가장 멀리 떨어진 거리를 탐색하면 아래와 같이 트리의 지름을 구할 수 있다.
자료구조 선택
여기에서는 DFS 알고리즘을 사용해서 전체 트리를 탐색한다. DFS 탐색을 위해서 아래와 같이 노드와 간선 구조체를 정의하였다.
간선 Edge 구조체는 다음의 변수를 가진다.
next: 다음 노드에 대한 정보. (다음 노드의 주소값)weight: 해당 간선의 가중치
Node 구조체는 다음의 변수를 가진다.
child: 자식 노드로 연결된 간선들depth: DFS 탐색 시 해당 노드의 깊이. -1인 경우 방문하지 않은 노드. 2번의 탐색을 진행하기 때문에 첫 번째 탐색 후 -1로 초기화 필요
struct Edge {
Edge(struct Node* _next, int _weight) : next(_next), weight(_weight) {}
Node* next;
int weight;
};
struct Node {
vector<Edge> child;
int depth{ -1 }; // -1인 경우 방문하지 않은 노드
};DFS 구현
DFS는 std::stack을 활용하여 구현한다. 이번에 구현할 DFS의 특징은 다음과 같다.
- 탐색 결과 하나의 말단 노드
endNode를 반환한다. - 입력 매개변수로 시작 노드
startNode를 받는다. - 매개변수
maxDist는 시작 노드에서부터 가장 멀리 있는 노드까지의 거리를 저장하는 쓰기용 매개변수로 활용한다.
Node* DFS(Node* start, int& maxDist)
{
Node* endNode{};
stack<Node*> s;
start->depth = 0;
s.push(start);
while (!s.empty())
{
Node* cur = s.top();
s.pop();
for (Edge edge : cur->child)
{
// 방문한적 없는 노드라면, 깊이 갱신 후 stack에 push
if (edge.next->depth == -1)
{
edge.next->depth = cur->depth + edge.weight;
s.push(edge.next);
// 가장 거리가 먼 노드의 정보와, 거리를 기록한다.
if (maxDist < edge.next->depth)
{
maxDist = edge.next->depth;
endNode = edge.next;
}
}
}
}
return endNode;
}전체 구현
첫 번째 DFS 탐색으로 하나의 말단 노드 endNode를 구하고, 두 번째 DFS에서는 endNode에서 시작해서 최대 거리를 구하여 반환한다.
#include <iostream>
#include <array>
#include <vector>
#include <stack>
#define endl '\n'
using namespace std;
struct Edge {
Edge(struct Node* _next, int _weight) : next(_next), weight(_weight) {}
Node* next;
int weight;
};
struct Node {
vector<Edge> child;
int depth{ -1 }; // -1인 경우 방문하지 않은 노드
};
Node* DFS(Node* start, int& maxDist)
{
Node* endNode{};
stack<Node*> s;
start->depth = 0;
s.push(start);
while (!s.empty())
{
Node* cur = s.top();
s.pop();
for (Edge edge : cur->child)
{
// 방문한적 없는 노드라면, 깊이 갱신 후 stack에 push
if (edge.next->depth == -1)
{
edge.next->depth = cur->depth + edge.weight;
s.push(edge.next);
if (maxDist < edge.next->depth)
{
maxDist = edge.next->depth;
endNode = edge.next;
}
}
}
}
return endNode;
}
int main() {
//입출력 성능향상을 위한 설정
ios_base::sync_with_stdio(false);
cout.tie(NULL);
cin.tie(NULL);
const int MAX = 100'001;
array<Node, MAX> tree;
int V; // (2 ≤ V ≤ 100,000)
cin >> V;
for (int i = 1; i <= V; ++i)
{
int cur;
cin >> cur;
while (1)
{
int vertex, weight;
cin >> vertex;
if (vertex == -1) break;
cin >> weight;
tree[cur].child.push_back(Edge(&tree[vertex], weight));
}
}
int maxDist{};
Node* endNode{};
endNode = DFS(&tree[1], maxDist);
// 깊이정보 초기화 (방문하지 않은 경우: -1)
for (int i = 1; i <= V; ++i)
{
tree[i].depth = -1;
}
DFS(endNode, maxDist);
cout << maxDist;
return 0;
}성능평가
이 알고리즘의 시간 복잡도를 따지기 위해서 반복문을 살펴보자. DFS의 반복문이 가장 비중이 크다. 첫번째 while문은 모든 노드를 방문한다. 그래서 노드의 개수를 \(V\) 라고 했을 때 최대 \(V\)번 실행된다. while문 안에 for문도 있다. 그런데 for문은 비록 이중 반복문으로 들어가 있지만, for문의 전체 반복횟수는 전체 간선의 수를 넘기지 않는다. 이 문제에서 간선의 수는 자식 노드의 수와 같기 때문에 최대 간선의 수는 \(2V\)이다. 때문이 이번 알고리즘의 시간 복잡도는 \(O(V)\)이다. 공간 복잡도 마찬가지로 \(O(V)\) 만큼의 공간이 필요하다.
