베스트앨범 (Level 3)
문제
전체 문제 보기
코딩테스트 연습 - 베스트앨범
스트리밍 사이트에서 장르 별로 가장 많이 재생된 노래를 두 개씩 모아 베스트 앨범을 출시하려 합니다. 노래는 고유 번호로 구분하며, 노래를 수록하는 기준은 다음과 같습니다. 속한 노래가
programmers.co.kr
접근법
이 문제에는 서로 연관된 3가지(장르, 재생횟수, 노래의 고유번호)의 데이터가 나온다. 각 데이터간의 관계를 어떻게 정의할지 그리고 어떤 자료구조를 사용할지가 중요하다. 필자는 해시테이블을 이용해서 문제를 풀었다. 해시테이블을 이용하면 다음과 같은 장점이 있다.
- 해시 테이블을 사용하면 데이터 입력과 탐색을 \(O(1)\)회에 처리할 수 있기에 전체 시간 복잡도를 \(O(n)\)로 비교적 빠르게 처리할 수 있다.
- 해시 함수가 문자열을 해싱하여 동작하는 방식이기 때문에 동일한 문자열에 대한 데이터 정리가 쉽다. (별도의 문자열 비교함수를 사용하지 않아도 된다.)
문제풀이에 사용할 자료구조를 선택하였으니 이제 해당 자료구조에 맞춰서 다음과 같이 데이터를 정리해볼 수 있다.
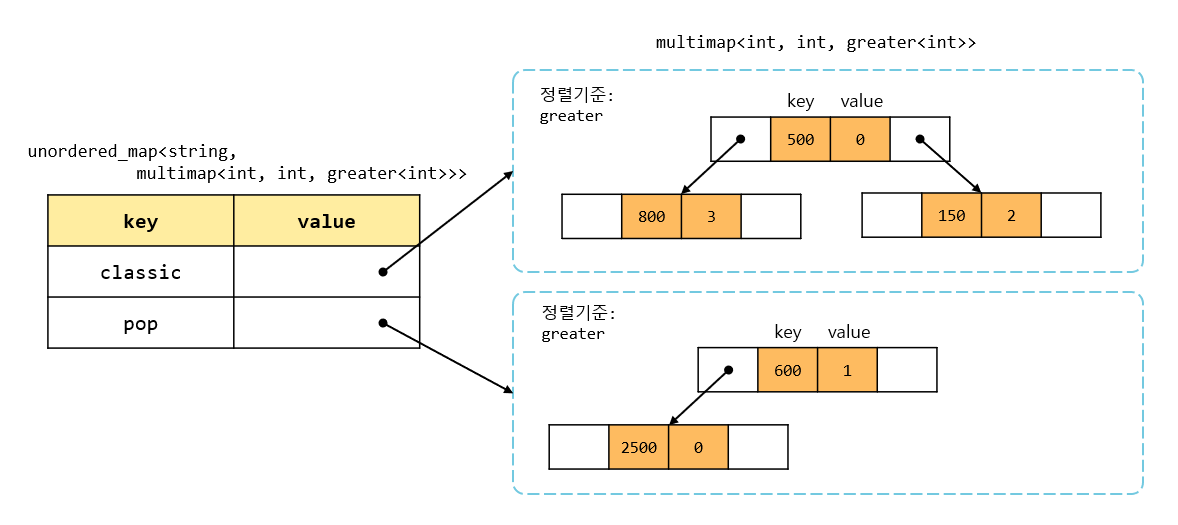
- 각 음악 장르별 총 재생 횟수 (해시맵<
key: 장르명 /value: 총 재생횟수>) - 각 음악 장르에 포함된 음악 목록. (해시맵<
key: 장르명 /value: 장르에 속한 노래 목록(멀티맵)>)- 각 음악 목록은 재생횟수를 기준으로 내림차순 정렬되어 있다. (멀티맵<
key: 재생횟수 /value: 노래 고유번호>
- 각 음악 목록은 재생횟수를 기준으로 내림차순 정렬되어 있다. (멀티맵<
(음악 목록을 map이 아니라 multimap으로 하는 이유는 문제에서 언급한 대로 재생횟수는 중복될 수 있기 때문이다.)
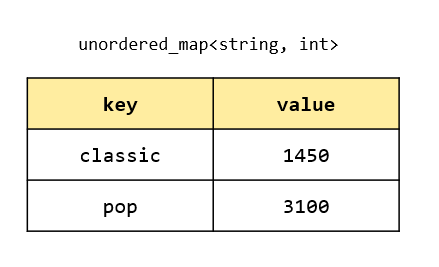
이를 표로 나타내면 다음과 같다.
이를 코드상으로 다음과 같이 선언 할 수 있다.
// key: 장르 이름 / value: 장르별 재생 횟수
unordered_map<string, int> ht_i;
// key: 장르이름 / value: 장르에 포함된 노래의 map(key: 노래의 재생 횟수, value: 노래 번호)
unordered_map<string, multimap<int, int, greater<int>>> ht_m; 우리가 최종적으로 해야할 일은 가장 많이 재생된 장르의 음악들을 먼저 출력하는 것이다. 아쉽게도 현재 우리가 가진 해시테이블로는 정렬을 할 수 없다. 그래서 정렬을 위한 별도의 map을 만들어 주자. (문제의 제한사항에서 모든 장르는 재생된 횟수가 다르다고 언급했으므로 굳이 multimap을 사용할 필요가 없다.)
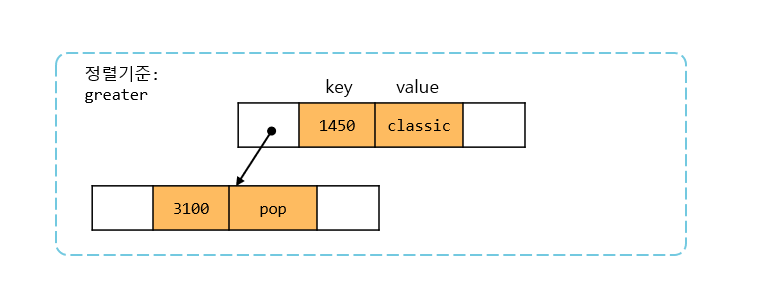
- 재생횟수에 해당하는 장르 (맵<
key: 총 재생횟수 /value: 장르명 / 내림차순 정렬>)
이를 표로 나타내면 다음과 같다.
이를 코드상으로 다음과 같이 선언 할 수 있다.
// key: 장르별 재생 횟수 / value: 장르 이름
map<int, string, greater<int>> mp;구현
이제는 각 자료구조에 데이터를 입력해주고, 최종결과를 answer에 저장하는일만 남았다. 이 작업은 아래 전체 코드의 주석을 참고하자.
#include <string>
#include <vector>
#include <unordered_map>
#include <map>
using namespace std;
vector<int> solution(vector<string> genres, vector<int> plays) {
vector<int> answer;
// key: 장르 이름 / value: 장르별 재생 횟수
unordered_map<string, int> ht_i;
// key: 장르이름 / value: 장르에 포함된 노래의 map(key: 노래의 재생 횟수, value: 노래 번호)
unordered_map<string, multimap<int, int, greater<int>>> ht_m;
// key: 장르별 재생 횟수 / value: 장르 이름
map<int, string, greater<int>> mp;
// 장르별 총 재생 횟수를 ht_i 해시 테이블에 저장
// 장르별 노래, 노래별 재생횟수를 ht_m 해시 테이블에 저장
for(int i = 0; i < genres.size(); i++)
{
ht_i[genres[i]] += plays[i];
ht_m[genres[i]].insert({plays[i],i});
}
// (장르별 총 재생횟수)를 가진 해시테이블을 재생횟수를 기준으로 정렬하기 위해서 mltimap에 저장
// multimap<key: 장르별 재생횟수, value: 장르 이름>
for(auto h : ht_i)
{
mp.insert({h.second,h.first});
}
// 각 장르별 재생횟수가 가장 많은 요소부터 반복문 실행
for(auto m : mp)
{
// 각 장르의 첫번째 원소(가장 많이 재생된 음악)를 가리키는 반복자 생성
auto iter = ht_m[m.second].begin();
// 첫 번째로 많이 재생된 음악을 answer에 저장
answer.push_back(iter->second);
// 두 번째 원소로 이동
iter++;
// 두 번째 음악이 존재한다면 두 번째 음악도 answer에 저장
if(iter != ht_m[m.second].end())
answer.push_back(iter->second);
}
return answer;
}